For decades, biologists have sampled life one layer at a time, characterizing genes, proteins, or metabolites in isolation. However, living systems are choreographed across numerous molecular levels, each affecting and reacting to the others in an ongoing dance. Multi-omics analysis is the scientific revolution that combines these disparate layers—genomics, transcriptomics, proteomics, metabolomics, epigenomics, microbiomics, and others, presenting a wide-angle, systems-level perspective on biology that any single method cannot1.
Single-omics analyses, though powerful, provide only a partial snapshot, somewhat similar to taking a solitary frame from a film. Multi-omics propels us beyond solitary visions to an integrative story, illuminating the complex interaction and regulatory networks that control cell function, disease state, and treatment response. It’s the aspiration to go beyond listing discrete components and, rather, to unravel the intricate connections that really control life.
The “omics” layers:
Central to multi-omics are its root layers, each giving a distinct view of biological systems:
Genomics
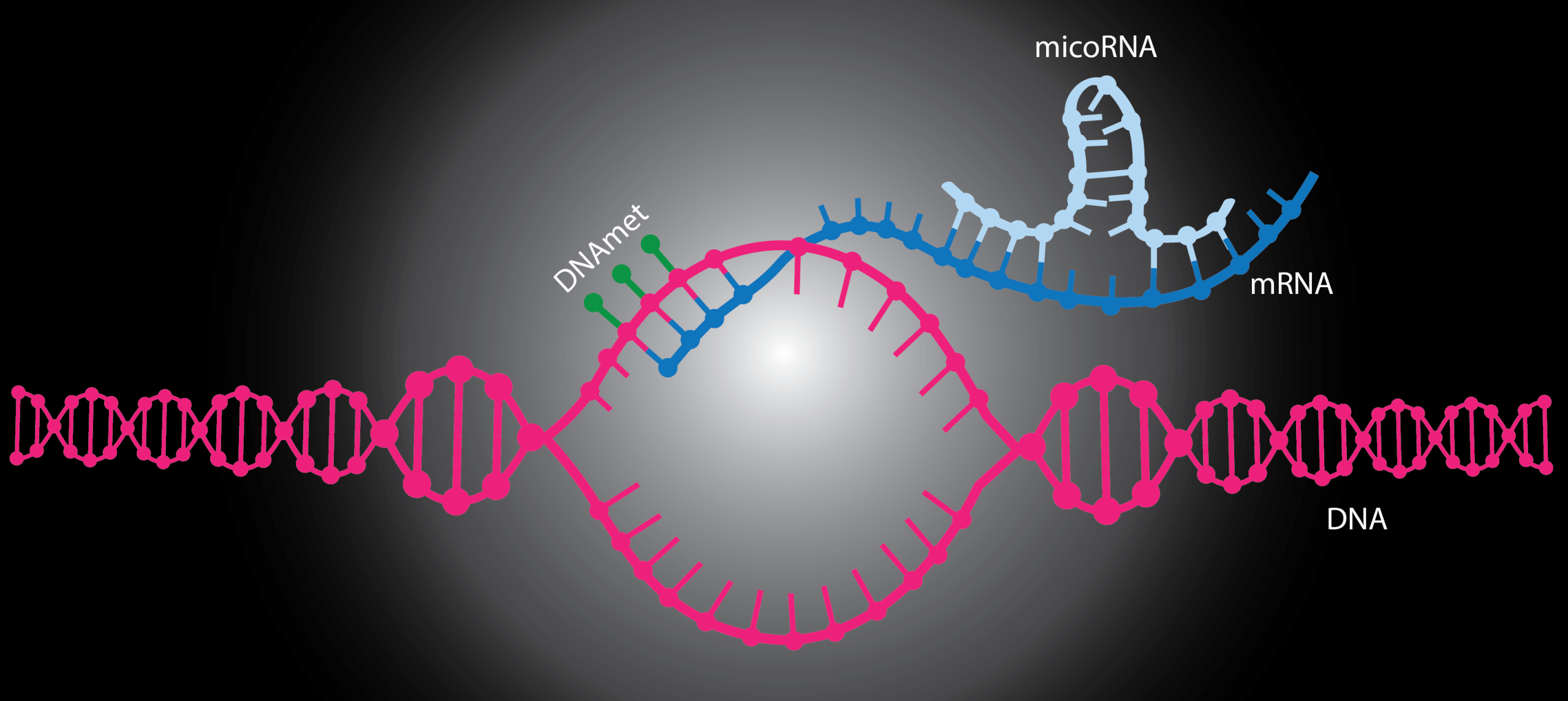
This analyzes the entire DNA instruction set in an organism, including all genes and gene differences2. It detects inherited mutations, structural variations, and genetic risk of disease. This is the blueprint, the fundamental code that determines what is possible in a cell or an organism.
Transcriptomics
This investigates the entire array of RNA transcripts that are made under defined conditions3. Transcriptomics, by measuring the activity of the genes that are expressed, offers a snapshot in time of cellular activity, revealing how the instructions are being read at any one point.
Proteomics
This investigates the proteome, the complete set of proteins synthesized by a cell or organism4. Proteins are the workhorses of biology, executing the instructions stored in DNA. Proteomics not only shows the proteins that are present, but also their abundance, modifications, and interactions, providing insight into how genetic information is translated into action.
Metabolomics
This targets small-molecule metabolites, the end products of cellular metabolism5. Such molecules capture the cell’s biochemical activity and well-being, and serve as a direct readout of metabolic pathways and physiological states.
Epigenomics
This explores chemical alterations to histone proteins and DNA (e.g. methylation and acetylation) that govern gene expression without modifying the DNA sequence itself6. These “epigenetic marks” are like notes on the blueprint, dictating which genes are on or off in response to development or environment.
Microbiomics or Metagenomics
This examines the genetic material of entire populations of microbes, such as the gut microbiome, or those found on the skin or in soil7. The microbiome has profound effects on health and disease, and combining its data with host-omics layers elucidates the intricate relationships between microbes and their hosts.
Other specialized “omics” disciplines—such as lipidomics (lipids), glycomics (sugars), and fluxomics (metabolic flux)—provide additional details, depending on the biological question8-10.
The Power of integration in the multi-omics approach
The actual strength of multi-omics lies in its capacity to interweave these disparate streams of data into a harmonious, multidimensional canvas. Such a combination provides researchers with a comprehensive overview of biological processes, tracing the path from genetic predisposition, through gene expression and protein function, to metabolic output and phenotypic outcome.
This integration unmasks dormant relationships, weak correlations, and regulatory networks that are not accessible using single-omics. A DNA variant may, for instance, affect gene expression, which in turn changes protein levels and eventually causes a shift in a metabolic pathway. Multi-omics can precisely identify molecular drivers of a disease, deconstruct compensatory mechanisms, and discover new therapeutic targets by charting upstream causes and downstream effects11, 12.
Multi-omics also enables the discovery of stable biomarkers of early disease detection, prognosis, and tracking treatment response13. By analyzing molecular alterations across multiple layers, scientists can identify biomarkers that are more sensitive and specific than those present in any one omics layer. This approach is driving the emergence of personalized medicine, enabling clinicians to personalize diagnostics and therapies based on the individual molecular profile of every patient14. In pharmaceutical research, multi-omics facilitates the identification of novel targets, elucidation of drug mechanisms, and prediction of side effects, accelerating the arrival of more effective and safer therapeutics15.
Methodology and challenges
Carrying out a multi-omics study is both an art and a science that involves skills across a range of technologies and analytical strategies. High-throughput technologies such as next-generation sequencing, mass spectrometry, and microarrays produce vast amounts of information from every omics layer16.
But the real challenge lies in the complexity and heterogeneity of these datasets17. Every type of omics generates data in varying formats, sizes, and units— counts, intensities, relative abundances, making integration quite a daunting task.
Handling these big datasets needs extensive computational power and storage, in addition to strong bioinformatics and computational biology skills. The integration process of the data generally encompasses a few important steps18:
Data pre-processing
The unprocessed data needs to be cleaned, normalized, and corrected for technical bias or batch effects. This makes datasets from various omics layers comparable and in a position to be effectively integrated.
Data integration
Advanced statistical models and algorithms, spanning early integration (concatenating data), late integration (processing each layer separately, then combining findings), to intermediate integration (learning joint representations), are employed for merging and analyzing diverse datasets19. Techniques range from joint dimensionality reduction, correlation analysis, network-based modeling, Bayesian and regression approaches, to increasingly, deep learning.
Data visualization
Developing intuitive, interactive visual representations of difficult multi-omics data is vital to enable interpretation and discovery20. Visualizations assist scientists to identify patterns, clusters, and outliers that may not be evident otherwise.
Statistical robustness
Checking if correlations and pathways observed are statistically significant and biologically relevant is important in order to prevent false discoveries. Stringent validation and cross-referencing against biological knowledge must be performed.
Biological Interpretation
Finally, computational results need to be interpreted as true biological understandings and hypotheses for experimental testing, a task that necessitates close communication between computational scientists and experimental biologists. Decrypting the biological meaning of integrated data, particularly when new or surprising patterns appear, involves stringent validation and frequently, novel experimental strategies.
How multi-omics is revolutionizing science
Multi-omics analysis is revolutionizing a broad spectrum of biomedical sciences:
Oncology
It is unveiling tumor heterogeneity, discovering new oncogenes and tumor suppressors, and unmasking resistance mechanisms to therapy21. Through the convergence of genomics, transcriptomics, proteomics, and metabolomics, scientists can design more accurate and personalized cancer therapies.
Neurodegenerative diseases
Multi-omics is helping to unravel the intricate etiology of neurodegenerative diseases such as Alzheimer’s and Parkinson’s22. Through the integration of genetic, proteomic, and metabolomic data, researchers are discovering early biomarkers, elucidating disease pathways, and identifying novel therapeutic targets.
Metabolic disorders
In disorders like obesity, diabetes, and cardiovascular disease, multi-omics links genetic risk to metabolic pathways and environmental factors, presenting a more comprehensive understanding of disease development and progression23.
Infectious diseases
In the context of infectious diseases and host-pathogen relationships, multi-omics explains how pathogens regulate host cells at several molecular levels and how the immune response is mounted24. This approach has been absolutely vital in understanding diseases such as COVID-1925.
Gerontology
Aging research is enriched by multi-omics through the detection of molecular aging signatures and pathways that could be targeted to enhance longevity26.
Microbiome research
In microbiome research, integrating microbial community data together with host omics reveals the intricate interactions between our microbiota and our well-being, with implications for everything, ranging from digestion to mental health27.
Drug discovery
Multi-omics is also driving drug repurposing, where drugs already in development are mapped onto molecular networks to identify novel applications, frequently at a fraction of the time and expense of conventional drug discovery28.
Multi-omics: revolutionizing systems biology and charting new frontiers
Multi-omics is more than a technological innovation—it’s a paradigm shift in the way we comprehend life. As multiple molecular layers are combined, researchers are deconstructing the intricacy of biology on a scale and depth previously unimaginable.
The landscape of multi-omics is evolving fast, with a number of thrilling frontiers on the way.
- Single-cell multi-omics can now enable scientists to profile various omics levels within single cells, resolving cellular heterogeneity and shedding light on how varying cell types make fate decisions during development, disease, and response to therapy29. Spatial multi-omics visualizes molecular data in tissue sections, retaining spatial context and providing novel insights into cell-cell interaction and tissue architecture in health and disease.
- Liquid biopsies are beginning to emerge as a non-invasive means to integrate multi-omics data from blood, urine, or other body fluids, facilitating early diagnosis, prognosis, and disease monitoring30.
- The advent of AI-driven discovery is enabling more cutting-edge algorithms to formulate hypotheses, propose experiments, and identify patterns in intricate data, speeding up the pace of discovery and translation31.
- With maturity in the field, comes setting priorities for standardization and reproducibility, where the efforts go towards developing robust protocols for data generation, analysis, and interpretation.
Ultimately, our goal is clinical translation: moving multi-omics discoveries at the bench to useful tools and therapies in the clinic, making precision medicine accessible to the general public32. With each advance in methodology and the broadening of applications, multi-omics holds the promise to revolutionize research, medicine, and our very comprehension of health and disease for generations to follow.